sparse – Symbolic Sparse Matrices#
The sparse submodule is not loaded when we import Aesara. You must
import aesara.sparse to enable it.
The sparse module provides the same functionality as the tensor module. The difference lies under the covers because sparse matrices do not store data in a contiguous array. The sparse module has been used in:
NLP: Dense linear transformations of sparse vectors.
Audio: Filterbank in the Fourier domain.
Compressed Sparse Format#
This section tries to explain how information is stored for the two sparse formats of SciPy supported by Aesara.
Aesara supports two compressed sparse formats: csc and csr,
respectively based on columns and rows. They have both the same
attributes: data, indices, indptr and shape.
The
dataattribute is a one-dimensionalndarraywhich contains all the non-zero elements of the sparse matrix.The
indicesandindptrattributes are used to store the position of the data in the sparse matrix.The
shapeattribute is exactly the same as theshapeattribute of a dense (i.e. generic) matrix. It can be explicitly specified at the creation of a sparse matrix if it cannot be inferred from the first three attributes.
CSC Matrix#
In the Compressed Sparse Column format, indices stands for
indexes inside the column vectors of the matrix and indptr tells
where the column starts in the data and in the indices
attributes. indptr can be thought of as giving the slice which
must be applied to the other attribute in order to get each column of
the matrix. In other words, slice(indptr[i], indptr[i+1])
corresponds to the slice needed to find the i-th column of the matrix
in the data and indices fields.
The following example builds a matrix and returns its columns. It prints the i-th column, i.e. a list of indices in the column and their corresponding value in the second list.
>>> import numpy as np
>>> import scipy.sparse as sp
>>> data = np.asarray([7, 8, 9])
>>> indices = np.asarray([0, 1, 2])
>>> indptr = np.asarray([0, 2, 3, 3])
>>> m = sp.csc_matrix((data, indices, indptr), shape=(3, 3))
>>> m.toarray()
array([[7, 0, 0],
[8, 0, 0],
[0, 9, 0]])
>>> i = 0
>>> m.indices[m.indptr[i]:m.indptr[i+1]], m.data[m.indptr[i]:m.indptr[i+1]]
(array([0, 1], dtype=int32), array([7, 8]))
>>> i = 1
>>> m.indices[m.indptr[i]:m.indptr[i+1]], m.data[m.indptr[i]:m.indptr[i+1]]
(array([2], dtype=int32), array([9]))
>>> i = 2
>>> m.indices[m.indptr[i]:m.indptr[i+1]], m.data[m.indptr[i]:m.indptr[i+1]]
(array([], dtype=int32), array([], dtype=int64))
CSR Matrix#
In the Compressed Sparse Row format, indices stands for indexes
inside the row vectors of the matrix and indptr tells where the
row starts in the data and in the indices
attributes. indptr can be thought of as giving the slice which
must be applied to the other attribute in order to get each row of the
matrix. In other words, slice(indptr[i], indptr[i+1]) corresponds
to the slice needed to find the i-th row of the matrix in the data
and indices fields.
The following example builds a matrix and returns its rows. It prints the i-th row, i.e. a list of indices in the row and their corresponding value in the second list.
>>> import numpy as np
>>> import scipy.sparse as sp
>>> data = np.asarray([7, 8, 9])
>>> indices = np.asarray([0, 1, 2])
>>> indptr = np.asarray([0, 2, 3, 3])
>>> m = sp.csr_matrix((data, indices, indptr), shape=(3, 3))
>>> m.toarray()
array([[7, 8, 0],
[0, 0, 9],
[0, 0, 0]])
>>> i = 0
>>> m.indices[m.indptr[i]:m.indptr[i+1]], m.data[m.indptr[i]:m.indptr[i+1]]
(array([0, 1], dtype=int32), array([7, 8]))
>>> i = 1
>>> m.indices[m.indptr[i]:m.indptr[i+1]], m.data[m.indptr[i]:m.indptr[i+1]]
(array([2], dtype=int32), array([9]))
>>> i = 2
>>> m.indices[m.indptr[i]:m.indptr[i+1]], m.data[m.indptr[i]:m.indptr[i+1]]
(array([], dtype=int32), array([], dtype=int64))
List of Implemented Operations#
- Moving from and to sparse
dense_from_sparse. Both grads are implemented. Structured by default.csr_from_dense,csc_from_dense. The grad implemented is structured.Aesara SparseVariable objects have a method
toarray()that is the same asdense_from_sparse.
- Construction of Sparses and their Properties
CSMandCSC,CSRto construct a matrix. The grad implemented is regular.csm_properties. to get the properties of a sparse matrix. The grad implemented is regular.csm_indices(x), csm_indptr(x), csm_data(x) and csm_shape(x) or x.shape.
sp_ones_like. The grad implemented is regular.sp_zeros_like. The grad implemented is regular.square_diagonal. The grad implemented is regular.construct_sparse_from_list. The grad implemented is regular.
- Cast
castwithbcast,wcast,icast,lcast,fcast,dcast,ccast, andzcast. The grad implemented is regular.
- Transpose
transpose. The grad implemented is regular.
- Basic Arithmetic
neg. The grad implemented is regular.eq.neq.gt.ge.lt.le.add. The grad implemented is regular.sub. The grad implemented is regular.mul. The grad implemented is regular.col_scaleto multiply by a vector along the columns. The grad implemented is structured.row_scaleto multiply by a vector along the rows. The grad implemented is structured.
- Monoid (Element-wise operation with only one sparse input).
They all have a structured grad.structured_sigmoidstructured_expstructured_logstructured_powstructured_minimumstructured_maximumstructured_addsinarcsintanarctansinharcsinhtanharctanhrad2degdeg2radrintceilfloortruncsgnlog1pexpm1squaresqrt
- Dot Product
dot.One of the inputs must be sparse, the other sparse or dense.
The grad implemented is regular.
No C code for perform and no C code for grad.
Returns a dense for perform and a dense for grad.
-
The first input is sparse, the second can be sparse or dense.
The grad implemented is structured.
C code for perform and grad.
It returns a sparse output if both inputs are sparse and dense one if one of the inputs is dense.
Returns a sparse grad for sparse inputs and dense grad for dense inputs.
-
The first input is sparse, the second can be sparse or dense.
The grad implemented is regular.
No C code for perform and no C code for grad.
Returns a Sparse.
The gradient returns a Sparse for sparse inputs and by default a dense for dense inputs. The parameter
grad_preserves_densecan be set to False to return a sparse grad for dense inputs.
sampling_dot.Both inputs must be dense.
The grad implemented is structured for
p.Sample of the dot and sample of the gradient.
C code for perform but not for grad.
Returns sparse for perform and grad.
usmm.- You shouldn’t insert this op yourself!
There is a rewrite that transforms a
dottoUsmmwhen possible.
This
Opis the equivalent of gemm for sparse dot.There is no grad implemented for this
Op.One of the inputs must be sparse, the other sparse or dense.
Returns a dense from perform.
- Slice Operations
sparse_variable[N, N], returns a tensor scalar. There is no grad implemented for this operation.
sparse_variable[M:N, O:P], returns a sparse matrix There is no grad implemented for this operation.
Sparse variables don’t support [M, N:O] and [M:N, O] as we don’t support sparse vectors and returning a sparse matrix would break the numpy interface. Use [M:M+1, N:O] and [M:N, O:O+1] instead.
diag. The grad implemented is regular.
- Probability
There is no grad implemented for these operations.PoissonandpoissonBinomialandcsc_fbinomial,csc_dbinomialcsr_fbinomial,csr_dbinomialMultinomialandmultinomial
- Internal Representation
They all have a regular grad implemented.ensure_sorted_indices.remove0.cleanto resort indices and remove zeros
- To help testing
tests.sparse.test_basic.sparse_random_inputs()
sparse – Sparse Op#
Classes for handling sparse matrices.
To read about different sparse formats, see http://www-users.cs.umn.edu/~saad/software/SPARSKIT/paper.ps
TODO: Automatic methods for determining best sparse format?
- class aesara.sparse.basic.AddSD[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
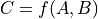 representing the function implemented by the
representing the function implemented by the Opand its two arguments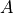 and
and 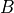 , given by the
, given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities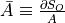 and
and
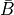 , for some scalar output term
, for some scalar output term 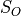 of
of 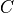 in
in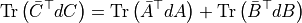
- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.AddSS[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.AddSSData[source]#
Add two sparse matrices assuming they have the same sparsity pattern.
Notes
The grad implemented is structured.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y)[source]#
- Parameters:
x – Sparse matrix.
y – Sparse matrix.
Notes
xandyare assumed to have the same sparsity pattern.
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.CSM(format, kmap=None)[source]#
Construct a CSM matrix from constituent parts.
Notes
The grad method returns a dense vector, so it provides a regular grad.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(data, indices, indptr, shape)[source]#
- Parameters:
data – One dimensional tensor representing the data of the sparse matrix to construct.
indices – One dimensional tensor of integers representing the indices of the sparse matrix to construct.
indptr – One dimensional tensor of integers representing the indice pointer for the sparse matrix to construct.
shape – One dimensional tensor of integers representing the shape of the sparse matrix to construct.
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.CSMGrad(kmap=None)[source]#
Compute the gradient of a CSM.
Note
CSM creates a matrix from data, indices, and indptr vectors; it’s gradient is the gradient of the data vector only. There are two complexities to calculate this gradient:
1. The gradient may be sparser than the input matrix defined by (data, indices, indptr). In this case, the data vector of the gradient will have less elements than the data vector of the input because sparse formats remove 0s. Since we are only returning the gradient of the data vector, the relevant 0s need to be added back. 2. The elements in the sparse dimension are not guaranteed to be sorted. Therefore, the input data vector may have a different order than the gradient data vector.
- make_node(x_data, x_indices, x_indptr, x_shape, g_data, g_indices, g_indptr, g_shape)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.CSMProperties(kmap=None)[source]#
Create arrays containing all the properties of a given sparse matrix.
More specifically, this
Opextracts the.data,.indices,.indptrand.shapefields.For specific field,
csm_data,csm_indices,csm_indptrandcsm_shapeare provided.Notes
The grad implemented is regular, i.e. not structured.
infer_shapemethod is not available for thisOp.We won’t implement infer_shape for this op now. This will ask that we implement an GetNNZ op, and this op will keep the dependence on the input of this op. So this won’t help to remove computations in the graph. To remove computation, we will need to make an infer_sparse_pattern feature to remove computations. Doing this is trickier then the infer_shape feature. For example, how do we handle the case when some op create some 0 values? So there is dependence on the values themselves. We could write an infer_shape for the last output that is the shape, but I dough this will get used.
We don’t return a view of the shape, we create a new ndarray from the shape tuple.
- grad(inputs, g)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(csm)[source]#
The output vectors correspond to the tuple
(data, indices, indptr, shape), i.e. the properties of acsmarray.- Parameters:
csm – Sparse matrix in
CSRorCSCformat.
- perform(node, inputs, out)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.Cast(out_type)[source]#
- grad(inputs, outputs_gradients)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.ColScaleCSC[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, s)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.ConstructSparseFromList[source]#
Constructs a sparse matrix out of a list of 2-D matrix rows.
Notes
The grad implemented is regular, i.e. not structured.
- R_op(inputs, eval_points)[source]#
Construct a graph for the R-operator.
This method is primarily used by
Rop.- Parameters:
inputs – The
Opinputs.eval_points – A
Variableor list ofVariables with the same length as inputs. Each element ofeval_pointsspecifies the value of the corresponding input at the point where the R-operator is to be evaluated.
- Return type:
rval[i]should beRop(f=f_i(inputs), wrt=inputs, eval_points=eval_points).
- grad(inputs, grads)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, values, ilist)[source]#
This creates a sparse matrix with the same shape as
x. Its values are the rows ofvaluesmoved. It operates similar to the following pseudo-code:output = csc_matrix.zeros_like(x, dtype=values.dtype) for in_idx, out_idx in enumerate(ilist): output[out_idx] = values[in_idx]
- Parameters:
x – A dense matrix that specifies the output shape.
values – A dense matrix with the values to use for output.
ilist – A dense vector with the same length as the number of rows of values. It specifies where in the output to put the corresponding rows.
- perform(node, inp, out_)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.DenseFromSparse(structured=True)[source]#
Convert a sparse matrix to a dense one.
Notes
The grad implementation can be controlled through the constructor via the
structuredparameter.Truewill provide a structured grad whileFalsewill provide a regular grad. By default, the grad is structured.- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.Diag[source]#
Extract the diagonal of a square sparse matrix as a dense vector.
Notes
The grad implemented is regular, i.e. not structured, since the output is a dense vector.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.Dot[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, out)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.EnsureSortedIndices(inplace)[source]#
Re-sort indices of a sparse matrix.
CSR column indices are not necessarily sorted. Likewise for CSC row indices. Use
ensure_sorted_indiceswhen sorted indices are required (e.g. when passing data to other libraries).Notes
The grad implemented is regular, i.e. not structured.
- grad(inputs, output_grad)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.GetItem2Lists[source]#
Select elements of sparse matrix, returning them in a vector.
- grad(inputs, g_outputs)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, ind1, ind2)[source]#
- Parameters:
x – Sparse matrix.
index – List of two lists, first list indicating the row of each element and second list indicating its column.
- perform(node, inp, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.GetItem2ListsGrad[source]#
- make_node(x, ind1, ind2, gz)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inp, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.GetItem2d[source]#
Implement a subtensor of sparse variable, returning a sparse matrix.
If you want to take only one element of a sparse matrix see
GetItemScalarthat returns a tensor scalar.Notes
Subtensor selection always returns a matrix, so indexing with [a:b, c:d] is forced. If one index is a scalar, for instance, x[a:b, c] or x[a, b:c], an error will be raised. Use instead x[a:b, c:c+1] or x[a:a+1, b:c].
The above indexing methods are not supported because the return value would be a sparse matrix rather than a sparse vector, which is a deviation from numpy indexing rule. This decision is made largely to preserve consistency between numpy and aesara. This may be revised when sparse vectors are supported.
The grad is not implemented for this op.
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.GetItemList[source]#
Select row of sparse matrix, returning them as a new sparse matrix.
- grad(inputs, g_outputs)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inp, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.GetItemListGrad[source]#
- make_node(x, index, gz)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inp, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.GetItemScalar[source]#
Subtensor of a sparse variable that takes two scalars as index and returns a scalar.
If you want to take a slice of a sparse matrix see
GetItem2dthat returns a sparse matrix.Notes
The grad is not implemented for this op.
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.HStack(format=None, dtype=None)[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(*mat)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, block, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.MulSD[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.MulSS[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.MulSV[source]#
Element-wise multiplication of sparse matrix by a broadcasted dense vector element wise.
Notes
The grad implemented is regular, i.e. not structured.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y)[source]#
- Parameters:
x – Sparse matrix to multiply.
y – Tensor broadcastable vector.
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.Neg[source]#
Negative of the sparse matrix (i.e. multiply by
-1).Notes
The grad is regular, i.e. not structured.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.Remove0(inplace=False)[source]#
Remove explicit zeros from a sparse matrix.
Notes
The grad implemented is regular, i.e. not structured.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.RowScaleCSC[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, s)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.SamplingDot[source]#
Compute the dot product
dot(x, y.T) = zfor only a subset ofz.This is equivalent to
p * (x . y.T)where*is the element-wise product,xandyoperands of the dot product andpis a matrix that contains 1 when the corresponding element ofzshould be calculated and0when it shouldn’t. Note thatSamplingDothas a different interface thandotbecause it requiresxto be am x kmatrix whileyis an x kmatrix instead of the usualk x nmatrix.Notes
It will work if the pattern is not binary value, but if the pattern doesn’t have a high sparsity proportion it will be slower then a more optimized dot followed by a normal elemwise multiplication.
The grad implemented is regular, i.e. not structured.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y, p)[source]#
- Parameters:
x – Tensor matrix.
y – Tensor matrix.
p – Sparse matrix in csr format.
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.SpSum(axis=None, sparse_grad=True)[source]#
WARNING: judgement call… We are not using the structured in the comparison or hashing because it doesn’t change the perform method therefore, we do want Sums with different structured values to be merged by the merge optimization and this requires them to compare equal.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.SparseFromDense(format)[source]#
Convert a dense matrix to a sparse matrix.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.SparseVariable(type: _TensorTypeType, owner: OptionalApplyType, index=None, name=None)[source]#
- class aesara.sparse.basic.SquareDiagonal[source]#
Produce a square sparse (csc) matrix with a diagonal given by a dense vector.
Notes
The grad implemented is regular, i.e. not structured.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.StructuredAddSV[source]#
Structured addition of a sparse matrix and a dense vector.
The elements of the vector are only added to the corresponding non-zero elements of the sparse matrix. Therefore, this operation outputs another sparse matrix.
Notes
The grad implemented is structured since the op is structured.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.StructuredDot[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(a, b)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.StructuredDotGradCSC[source]#
- c_code(node, name, inputs, outputs, sub)[source]#
Return the C implementation of an
Op.Returns C code that does the computation associated to this
Op, given names for the inputs and outputs.- Parameters:
node (Apply instance) – The node for which we are compiling the current C code. The same
Opmay be used in more than one node.name (str) – A name that is automatically assigned and guaranteed to be unique.
inputs (list of strings) – There is a string for each input of the function, and the string is the name of a C variable pointing to that input. The type of the variable depends on the declared type of the input. There is a corresponding python variable that can be accessed by prepending
"py_"to the name in the list.outputs (list of strings) – Each string is the name of a C variable where the
Opshould store its output. The type depends on the declared type of the output. There is a corresponding Python variable that can be accessed by prepending"py_"to the name in the list. In some cases the outputs will be preallocated and the value of the variable may be pre-filled. The value for an unallocated output is type-dependent.sub (dict of strings) – Extra symbols defined in
CLinkersub symbols (such as'fail').
- c_code_cache_version()[source]#
Return a tuple of integers indicating the version of this
Op.An empty tuple indicates an “unversioned”
Opthat will not be cached between processes.The cache mechanism may erase cached modules that have been superseded by newer versions. See
ModuleCachefor details.See also
c_code_cache_version_apply
- make_node(a_indices, a_indptr, b, g_ab)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.StructuredDotGradCSR[source]#
- c_code(node, name, inputs, outputs, sub)[source]#
Return the C implementation of an
Op.Returns C code that does the computation associated to this
Op, given names for the inputs and outputs.- Parameters:
node (Apply instance) – The node for which we are compiling the current C code. The same
Opmay be used in more than one node.name (str) – A name that is automatically assigned and guaranteed to be unique.
inputs (list of strings) – There is a string for each input of the function, and the string is the name of a C variable pointing to that input. The type of the variable depends on the declared type of the input. There is a corresponding python variable that can be accessed by prepending
"py_"to the name in the list.outputs (list of strings) – Each string is the name of a C variable where the
Opshould store its output. The type depends on the declared type of the output. There is a corresponding Python variable that can be accessed by prepending"py_"to the name in the list. In some cases the outputs will be preallocated and the value of the variable may be pre-filled. The value for an unallocated output is type-dependent.sub (dict of strings) – Extra symbols defined in
CLinkersub symbols (such as'fail').
- c_code_cache_version()[source]#
Return a tuple of integers indicating the version of this
Op.An empty tuple indicates an “unversioned”
Opthat will not be cached between processes.The cache mechanism may erase cached modules that have been superseded by newer versions. See
ModuleCachefor details.See also
c_code_cache_version_apply
- make_node(a_indices, a_indptr, b, g_ab)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.Transpose[source]#
Transpose of a sparse matrix.
Notes
The returned matrix will not be in the same format.
cscmatrix will be changed incsrmatrix andcsrmatrix incscmatrix.The grad is regular, i.e. not structured.
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.TrueDot(grad_preserves_dense=True)[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(x, y)[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- perform(node, inp, out_)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.Usmm[source]#
Computes the dense matrix resulting from
alpha * x @ y + z.Notes
At least one of
xorymust be a sparse matrix.- make_node(alpha, x, y, z)[source]#
- Parameters:
alpha – A scalar.
x – Matrix variable.
y – Matrix variable.
z – Dense matrix.
- perform(node, inputs, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- class aesara.sparse.basic.VStack(format=None, dtype=None)[source]#
- grad(inputs, gout)[source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
representing the function implemented by the Opand its two arguments and , given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities and
, for some scalar output term of
in- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- perform(node, block, outputs)[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- aesara.sparse.basic.add(x, y)[source]#
Add two matrices, at least one of which is sparse.
This method will provide the right op according to the inputs.
- Parameters:
x – A matrix variable.
y – A matrix variable.
- Returns:
x+y- Return type:
A sparse matrix
Notes
At least one of
xandymust be a sparse matrix.The grad will be structured only when one of the variable will be a dense matrix.
- aesara.sparse.basic.as_sparse(x, name=None, ndim=None, **kwargs)[source]#
Wrapper around SparseVariable constructor to construct a Variable with a sparse matrix with the same dtype and format.
- Parameters:
x – A sparse matrix.
- Returns:
SparseVariable version of
x.- Return type:
object
- aesara.sparse.basic.as_sparse_variable(x, name=None, ndim=None, **kwargs)[source]#
Wrapper around SparseVariable constructor to construct a Variable with a sparse matrix with the same dtype and format.
- Parameters:
x – A sparse matrix.
- Returns:
SparseVariable version of
x.- Return type:
object
- aesara.sparse.basic.cast(variable, dtype)[source]#
Cast sparse variable to the desired dtype.
- Parameters:
variable – Sparse matrix.
dtype – The dtype wanted.
- Return type:
Same as
xbut havingdtypeas dtype.
Notes
The grad implemented is regular, i.e. not structured.
- aesara.sparse.basic.clean(x)[source]#
Remove explicit zeros from a sparse matrix, and re-sort indices.
CSR column indices are not necessarily sorted. Likewise for CSC row indices. Use
cleanwhen sorted indices are required (e.g. when passing data to other libraries) and to ensure there are no zeros in the data.- Parameters:
x – A sparse matrix.
- Returns:
The same as
xwith indices sorted and zeros removed.- Return type:
A sparse matrix
Notes
The grad implemented is regular, i.e. not structured.
- aesara.sparse.basic.col_scale(x, s)[source]#
Scale each columns of a sparse matrix by the corresponding element of a dense vector.
- Parameters:
x – A sparse matrix.
s – A dense vector with length equal to the number of columns of
x.
- Returns:
A sparse matrix in the same format as
xwhich each column had beenmultiply by the corresponding element of
s.
Notes
The grad implemented is structured.
- aesara.sparse.basic.dot(x, y)[source]#
Efficiently compute the dot product when one or all operands are sparse.
Supported formats are CSC and CSR. The output of the operation is dense.
- Parameters:
x – Sparse or dense matrix variable.
y – Sparse or dense matrix variable.
- Return type:
The dot product
x @ yin a dense format.
Notes
The grad implemented is regular, i.e. not structured.
At least one of
xorymust be a sparse matrix.When the operation has the form
dot(csr_matrix, dense)the gradient of this operation can be performed inplace byUsmmCscDense. This leads to significant speed-ups.
- aesara.sparse.basic.hstack(blocks, format=None, dtype=None)[source]#
Stack sparse matrices horizontally (column wise).
This wrap the method hstack from scipy.
- Parameters:
blocks – List of sparse array of compatible shape.
format – String representing the output format. Default is csc.
dtype – Output dtype.
- Returns:
The concatenation of the sparse array column wise.
- Return type:
array
Notes
The number of line of the sparse matrix must agree.
The grad implemented is regular, i.e. not structured.
- aesara.sparse.basic.mul(x, y)[source]#
Multiply elementwise two matrices, at least one of which is sparse.
This method will provide the right op according to the inputs.
- Parameters:
x – A matrix variable.
y – A matrix variable.
- Returns:
x*y- Return type:
A sparse matrix
Notes
At least one of
xandymust be a sparse matrix. The grad is regular, i.e. not structured.
- aesara.sparse.basic.row_scale(x, s)[source]#
Scale each row of a sparse matrix by the corresponding element of a dense vector.
- Parameters:
x – A sparse matrix.
s – A dense vector with length equal to the number of rows of
x.
- Returns:
A sparse matrix in the same format as
xwhose each row has been multiplied by the corresponding element ofs.- Return type:
A sparse matrix
Notes
The grad implemented is structured.
- aesara.sparse.basic.sp_ones_like(x)[source]#
Construct a sparse matrix of ones with the same sparsity pattern.
- Parameters:
x – Sparse matrix to take the sparsity pattern.
- Returns:
The same as
xwith data changed for ones.- Return type:
A sparse matrix
- aesara.sparse.basic.sp_sum(x, axis=None, sparse_grad=False)[source]#
Calculate the sum of a sparse matrix along the specified axis.
It operates a reduction along the specified axis. When
axisisNone, it is applied along all axes.- Parameters:
x – Sparse matrix.
axis – Axis along which the sum is applied. Integer or
None.sparse_grad (bool) –
Trueto have a structured grad.
- Returns:
The sum of
xin a dense format.- Return type:
object
Notes
The grad implementation is controlled with the
sparse_gradparameter.Truewill provide a structured grad andFalsewill provide a regular grad. For both choices, the grad returns a sparse matrix having the same format asx.This op does not return a sparse matrix, but a dense tensor matrix.
- aesara.sparse.basic.sp_zeros_like(x)[source]#
Construct a sparse matrix of zeros.
- Parameters:
x – Sparse matrix to take the shape.
- Returns:
The same as
xwith zero entries for all element.- Return type:
A sparse matrix
- aesara.sparse.basic.sparse_formats = ['csc', 'csr'][source]#
Types of sparse matrices to use for testing.
- aesara.sparse.basic.structured_dot(x, y)[source]#
Structured Dot is like dot, except that only the gradient wrt non-zero elements of the sparse matrix
aare calculated and propagated.The output is presumed to be a dense matrix, and is represented by a TensorType instance.
- Parameters:
a – A sparse matrix.
b – A sparse or dense matrix.
- Returns:
The dot product of
aandb.- Return type:
A sparse matrix
Notes
The grad implemented is structured.
- aesara.sparse.basic.sub(x, y)[source]#
Subtract two matrices, at least one of which is sparse.
This method will provide the right op according to the inputs.
- Parameters:
x – A matrix variable.
y – A matrix variable.
- Returns:
x-y- Return type:
A sparse matrix
Notes
At least one of
xandymust be a sparse matrix.The grad will be structured only when one of the variable will be a dense matrix.
- aesara.sparse.basic.true_dot(x, y, grad_preserves_dense=True)[source]#
Operation for efficiently calculating the dot product when one or all operands are sparse. Supported formats are CSC and CSR. The output of the operation is sparse.
- Parameters:
x – Sparse matrix.
y – Sparse matrix or 2d tensor variable.
grad_preserves_dense (bool) – If True (default), makes the grad of dense inputs dense. Otherwise the grad is always sparse.
- Returns:
The dot product
x.`y` in a sparse format.Notex
—–
The grad implemented is regular, i.e. not structured.
- aesara.sparse.basic.vstack(blocks, format=None, dtype=None)[source]#
Stack sparse matrices vertically (row wise).
This wrap the method vstack from scipy.
- Parameters:
blocks – List of sparse array of compatible shape.
format – String representing the output format. Default is csc.
dtype – Output dtype.
- Returns:
The concatenation of the sparse array row wise.
- Return type:
array
Notes
The number of column of the sparse matrix must agree.
The grad implemented is regular, i.e. not structured.