graph – Objects and functions for computational graphs#
- class aesara.graph.op.HasInnerGraph[source]#
A mixin for an
Opthat contain an inner graph.- fgraph: FunctionGraph[source]#
A
FunctionGraphof the inner function.
- class aesara.graph.op.Op[source]#
A class that models and constructs operations in a graph.
A
Opinstance has several responsibilities:construct
Applynodes viaOp.make_node()method,perform the numeric calculation of the modeled operation via the
Op.perform()method,and (optionally) build the gradient-calculating sub-graphs via the
Op.grad()method.
To see how
Op,Type,Variable, andApplyfit together see the page on graph – Interface for the Aesara graph.For more details regarding how these methods should behave: see the
Op Contractin the sphinx docs (advanced tutorial onOpmaking).- L_op(inputs: Sequence[Variable], outputs: Sequence[Variable], output_grads: Sequence[Variable]) List[Variable][source]#
Construct a graph for the L-operator.
The L-operator computes a row vector times the Jacobian.
This method dispatches to
Op.grad()by default. In one sense, this method provides the original outputs when they’re needed to compute the return value, whereasOp.graddoesn’t.See
Op.gradfor a mathematical explanation of the inputs and outputs of this method.
- R_op(inputs: List[Variable], eval_points: Variable | List[Variable]) List[Variable][source]#
Construct a graph for the R-operator.
This method is primarily used by
Rop.- Parameters:
inputs – The
Opinputs.eval_points – A
Variableor list ofVariables with the same length as inputs. Each element ofeval_pointsspecifies the value of the corresponding input at the point where the R-operator is to be evaluated.
- Return type:
rval[i]should beRop(f=f_i(inputs), wrt=inputs, eval_points=eval_points).
- static add_tag_trace(thing: T, user_line: int | None = None) T[source]#
Add tag.trace to a node or variable.
The argument is returned after being affected (inplace).
- Parameters:
thing – The object where we add .tag.trace.
user_line – The max number of user line to keep.
Notes
We also use config.traceback__limit for the maximum number of stack level we look.
- default_output: int | None = None[source]#
An
intthat specifies which outputOp.__call__()should return. IfNone, then all outputs are returned.A subclass should not change this class variable, but instead override it with a subclass variable or an instance variable.
- destroy_map: Dict[int, List[int]] = {}[source]#
A
dictthat maps output indices to the input indices upon which they operate in-place.Examples
destroy_map = {0: [1]} # first output operates in-place on second input destroy_map = {1: [0]} # second output operates in-place on first input
- do_constant_folding(fgraph: FunctionGraph, node: Apply) bool[source]#
Determine whether or not constant folding should be performed for the given node.
This allows each
Opto determine if it wants to be constant folded when all its inputs are constant. This allows it to choose where it puts its memory/speed trade-off. Also, it could make things faster as constants can’t be used for in-place operations (see*IncSubtensor).- Parameters:
node (Apply) – The node for which the constant folding determination is made.
- Returns:
res
- Return type:
bool
- get_params(node: Apply) Params[source]#
Try to get parameters for the
OpwhenOp.params_typeis set to aParamsType.
- grad(inputs: Sequence[Variable], output_grads: Sequence[Variable]) List[Variable][source]#
Construct a graph for the gradient with respect to each input variable.
Each returned
Variablerepresents the gradient with respect to that input computed based on the symbolic gradients with respect to each output. If the output is not differentiable with respect to an input, then this method should return an instance of typeNullTypefor that input.Using the reverse-mode AD characterization given in [1]_, for a
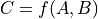 representing the function implemented by the
representing the function implemented by the Opand its two arguments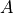 and
and 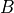 , given by the
, given by the
Variables ininputs, the values returned byOp.gradrepresent the quantities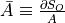 and
and
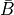 , for some scalar output term
, for some scalar output term 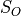 of
of 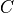 in
in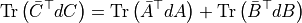
- Parameters:
inputs – The input variables.
output_grads – The gradients of the output variables.
- Returns:
grads – The gradients with respect to each
Variableininputs... [1] Giles, Mike. 2008. “An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Automatic Differentiation.”
- make_node(*inputs: Variable) Apply[source]#
Construct an
Applynode that represent the application of this operation to the given inputs.This must be implemented by sub-classes.
- Returns:
node – The constructed
Applynode.- Return type:
- make_py_thunk(node: Apply, storage_map: Dict[Variable, List[Any | None]], compute_map: Dict[Variable, List[bool]], no_recycling: List[Variable], debug: bool = False) ThunkType[source]#
Make a Python thunk.
Like
Op.make_thunk()but only makes Python thunks.
- make_thunk(node: Apply, storage_map: Dict[Variable, List[Any | None]], compute_map: Dict[Variable, List[bool]], no_recycling: List[Variable], impl: str | None = None) ThunkType[source]#
Create a thunk.
This function must return a thunk, that is a zero-arguments function that encapsulates the computation to be performed by this op on the arguments of the node.
- Parameters:
node – Something previously returned by
Op.make_node().storage_map – A
dictmappingVariables to single-element lists where a computed value for eachVariablemay be found.compute_map – A
dictmappingVariables to single-element lists where a boolean value can be found. The boolean indicates whether theVariable’sstorage_mapcontainer contains a valid value (i.e.True) or whether it has not been computed yet (i.e.False).no_recycling – List of
Variables for which it is forbidden to reuse memory allocated by a previous call.impl (str) – Description for the type of node created (e.g.
"c","py", etc.)
Notes
If the thunk consults the
storage_mapon every call, it is safe for it to ignore theno_recyclingargument, because elements of theno_recyclinglist will have a value ofNonein thestorage_map. If the thunk can potentially cache return values (likeCLinkerdoes), then it must not do so for variables in theno_recyclinglist.Op.prepare_node()is always called. If it tries'c'and it fails, then it tries'py', andOp.prepare_node()will be called twice.
- abstract perform(node: Apply, inputs: Sequence[Any], output_storage: List[List[Any | None]], params: Tuple[Any] | None = None) None[source]#
Calculate the function on the inputs and put the variables in the output storage.
- Parameters:
node – The symbolic
Applynode that represents this computation.inputs – Immutable sequence of non-symbolic/numeric inputs. These are the values of each
Variableinnode.inputs.output_storage – List of mutable single-element lists (do not change the length of these lists). Each sub-list corresponds to value of each
Variableinnode.outputs. The primary purpose of this method is to set the values of these sub-lists.params – A tuple containing the values of each entry in
Op.__props__.
Notes
The
output_storagelist might contain data. If an element of output_storage is notNone, it has to be of the right type, for instance, for aTensorVariable, it has to be a NumPyndarraywith the right number of dimensions and the correct dtype. Its shape and stride pattern can be arbitrary. It is not guaranteed that such pre-set values were produced by a previous call to thisOp.perform(); they could’ve been allocated by anotherOp’sperformmethod. AnOpis free to reuseoutput_storageas it sees fit, or to discard it and allocate new memory.
- prepare_node(node: Apply, storage_map: Dict[Variable, List[Any | None]] | None, compute_map: Dict[Variable, List[bool]] | None, impl: str | None) None[source]#
Make any special modifications that the
Opneeds before doingOp.make_thunk().This can modify the node inplace and should return nothing.
It can be called multiple time with different
implvalues.Warning
It is the
Op’s responsibility to not re-prepare the node when it isn’t good to do so.
- aesara.graph.op.compute_test_value(node: Apply)[source]#
Computes the test value of a node.
- Parameters:
node (Apply) – The
Applynode for which the test value is computed.- Returns:
The
tag.test_values are updated in eachVariableinnode.outputs.- Return type:
None
- aesara.graph.op.get_test_value(v: Any) Any[source]#
Get the test value for
v.If input
vis not already a variable, it is turned into one by callingas_tensor_variable(v).- Raises:
AttributeError` if no test value is set –
- aesara.graph.op.get_test_values(*args: Variable) Any | List[Any][source]#
Get test values for multiple
Variables.Intended use:
for val_1, ..., val_n in get_debug_values(var_1, ..., var_n): if some condition on val_1, ..., val_n is not met: missing_test_message("condition was not met")
Given a list of variables,
get_debug_valuesdoes one of three things:If the interactive debugger is off, returns an empty list
If the interactive debugger is on, and all variables have debug values, returns a list containing a single element. This single element is either:
- if there is only one variable, the element is its
value
- otherwise, a tuple containing debug values of all
the variables.
If the interactive debugger is on, and some variable does not have a debug value, issue a
missing_test_messageabout the variable, and, if still in control of execution, return an empty list.
- aesara.graph.op.missing_test_message(msg: str) None[source]#
Display a message saying that some test_value is missing.
This uses the appropriate form based on
config.compute_test_value:- off:
The interactive debugger is off, so we do nothing.
- ignore:
The interactive debugger is set to ignore missing inputs, so do nothing.
- warn:
Display
msgas a warning.
- Raises:
AttributeError – With msg as the exception text.